Practical guide to run llama2 locally
Content
- Overview: The problem statement
- Quantize the llama2-7b-chat model
- Load and Run the model
- Challenges and Considerations
- Endnotes
- References
Overview: The problem statement
The LLMs(Large Language Models), as the word ‘Large’ in their name, are very large in size(in terms of number of parameters and the space that they take on disk and memory). The llama2 series models by meta for example comes in 3 variants as below:-
- Llama2-7B-Chat: 7 Billion parameters and ~14 GB in disk-size
- Llama2-13B-Chat: 13 Billion parameters and ~26 GB in disk-size
- Llama2-70B-Chat: 70 Billion parameters and ~140 GB in disk-size
The parameters are basically float16 numbers which take 2 bytes for each parameter.
So to load them into memory and then making predictions from them is quite complex and expensive task in terms of:-
- Memory requirements
- Prediction latency
Thus to provide a potential solution to the above problems there is this process called model-quantization. Quantization is a technique that reduces the precision of the weights and activations in a neural network. This can lead to a significant reduction in the model size, as well as an improvement in inference speed.
In this blog-post we will be seeing how to quantize the llama2-7b-chat (the same technique can be applied to other variants of the llama2 series models as well) model so that it can be loaded into local cpu system and make successful prediction from it with fairly good performance. This is like having our own LLM to talk to with no fear of getting our prompts copied by some external systems. Let’s dive in…
Quantize the llama2-7b-chat model
Below are the steps to create the quantized version of the model and run it locally in a cpu based system. The given process has been successfully applied on Linux(Ubuntu) os with 12 GB RAM and core i5 processor.
Step-1: Request the access to download the llama2 model from the meta ai website
Step-2: Clone the below 2 repositories:-
git clone https://github.com/facebookresearch/llama.git
git clone https://github.com/ggerganov/llama.cpp.git
Step-3: Navigate into the llama repository and run the below command:-
/bin/bash ./download.sh
follow the instructions on screen to download the model. As a result you will have a llama-2–7b-chat directory created with the model files in it.
Step-4: Now in order to quantize the model first it needs to be converted in f16(float16) format first. For that first Navigate to the llama.cpp directory then run:-
make
python3 -m pip install -r requirements.txt
python3 convert.py --outfile models/7B/ggml-model-f16.bin --outtype f16 ../llama/llama-2-7b-chat --vocab-dir ../llama
./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.bin q4_0
The convert command is used to create the equivalent f16 file from the original model file. This is needed in order to create the quantized version of the model. Thus with the above convert.py command the model file will be converted into f16 format file ggml-model-f16.bin. This would be roughly equal to the size of the original model file. Then this f16 file is used to create the 4-bit quantized version of the model which would be roughly 4 times less (~3.8GB) than the original model file.
Load and Run the model
We are all set to run the model and chat with it. Run the below command to load the quantized model into the memory and chat with our own llm:-
./main -m ./models/7B/ggml-model-q4_0.bin -n 1024 --repeat_penalty 1.0 --color -i -r "User:" -f ./prompts/chat-with-bob.txt
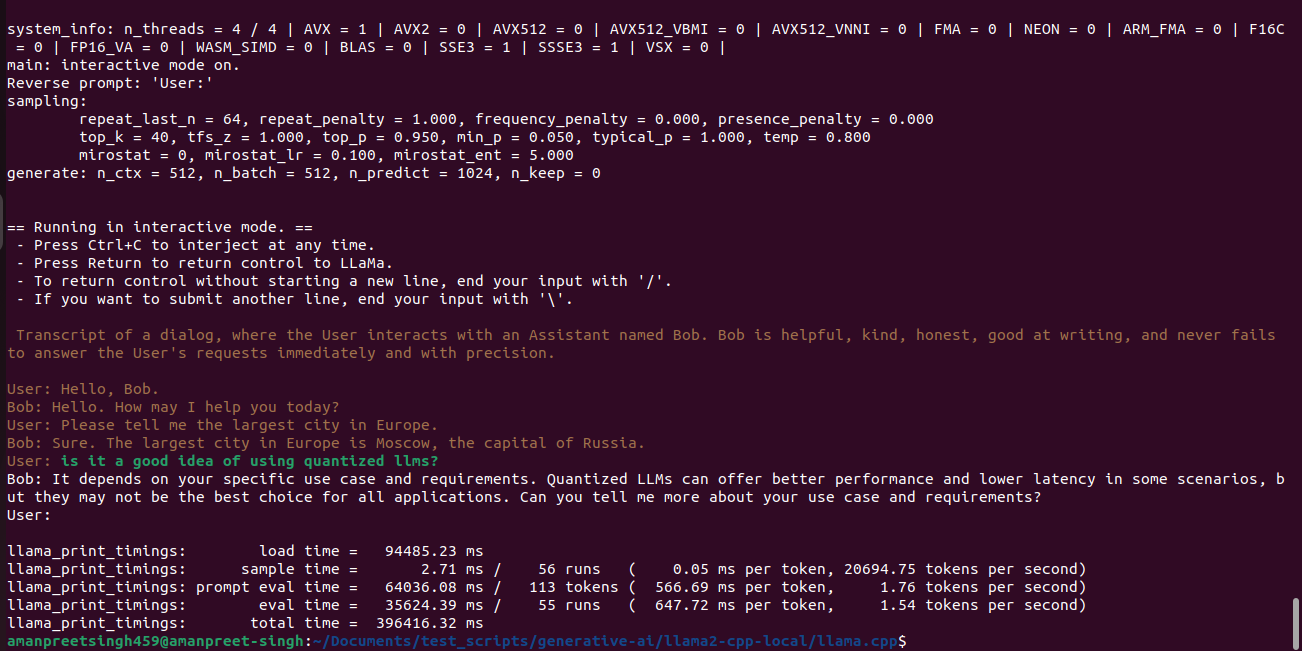
The model which had been created using the above guide has been uploaded to the huggingface. That can be downloaded and used directly. Get the model here
Challenges and Considerations
While quantization offers numerous advantages, it also presents some challenges:
- Accuracy loss: Quantization can lead to a slight decrease in accuracy compared to full-precision models. However, careful implementation and fine-tuning can minimize this loss. Hardware compatibility: Not all hardware supports quantized models, which may limit their deployment options.
- Technical complexity: Quantization requires specific expertise and tools, adding an additional layer of complexity to the model development process.
Endnotes
Despite the challenges, the field of LLM quantization is rapidly evolving. Researchers are developing new methods to achieve high accuracy with minimal loss, and hardware manufacturers are adding support for quantized models.
The future of LLMs lies in making them smaller, faster, and more accessible. Quantization plays a crucial role in achieving this goal, paving the way for a wider range of applications and a more democratized AI landscape.
Hope you enjoyed the post…