Introduction and Implementation guide on LLM fine-tuning using LoRA
Content
- Overview: What is LLM fine-tuning?
- Why fine-tune LLMs?
- How to fine-tune LLMs?
- LoRA: Low Rank Adaptation
- Implementation: Fine-tuning Llama 2 with LoRA
- Endnotes
- References
Overview: What is LLM fine-tuning?
The currently available LLMs which are currently available such as ChatGPT, LLAMA2, Falcon etc. are very general-purpose LLMs. The full potential of an LLM is very hard to realize with just instructions prompting and/or showing some examples as part of the prompt. And that too on the general domain data on which the LLM has been trained on.
Fine-tuning is a technique used to improve the performance of large language models (LLMs) on specific tasks or domains. It involves retraining an LLM that has already been trained on a massive dataset of general-purpose text data on a smaller dataset of task-specific data.
Why fine-tune LLMs?
There are several reasons why fine-tuning LLMs can be beneficial. Few of them are below:-
Improved performance on specific tasks: Fine-tuning can significantly improve the performance of LLMs on specific tasks. For example, fine-tuning an LLM on a dataset of legal documents can improve its ability to generate summaries of legal cases. Or fine-tuning an LLM on a dataset of Shakespeare poems can really surprise us with its poem writing capabilities.
Domain adaptation: Fine-tuning can help LLMs to adapt to the nuances of specific domains. For example, fine-tuning an LLM on a dataset of medical documents can improve its ability to generate medical reports.
Reduced data requirements: Fine-tuning can reduce the amount of data that is needed to train an LLM for a specific task. This is because fine-tuning allows the LLM to leverage the knowledge that it has already learned from the general-purpose training data.
Increased interpretability: Fine-tuning can make LLMs more interpretable. This is because fine-tuning can help to identify the features of the input data that are most important for the task at hand.
How to fine-tune LLMs?
The fine-tuning process typically involves the following steps:
1. Collect a dataset of task-specific data: The dataset should be representative of the task that the fine-tuned LLM will be used for. Although there is not a fixed amount of data that would guarantee the desired performance on the specific task. It can vary from task-to-task
2. Preprocess the data: This may involve cleaning the data, removing noise, and formatting the data in a way that is compatible with the LLM. It’s just like preprocessing the data for any traditional ML algorithm.
3. Choose a fine-tuning method: There are a number of different fine-tuning methods available. Some common methods include:-
- Full fine-tuning: This involves fine-tuning all of the parameters in the LLM.
- Layer-wise fine-tuning: This involves fine-tuning only the parameters in the top few layers of the LLM.
- Adapter-based fine-tuning: This involves adding a small number of adapter modules to the LLM. This method is also called “Parameter Efficient Fine-Tuning (PEFT)”. LoRA is a popular method of doing this. We will discuss LoRA in detail in the next section.
LoRA: Low Rank Adaptation
The Large Language Models(LLMs) as there is large word in the definition, are massive in size. The model parameters make up the size of the LLMs. Few examples of large models and their sizes:-
- GPT-2: 1.5-billion-parameters model
- GPT-3: 175-billion-parameters model
- PaLM: 540-billion-parameters model
So retraining them(from scratch) can be very expensive and time-consuming. As during training we need to load the entire model weights (parameters) into the memory. Then as backpropagation involves in the process of training, the gradients get calculated, we would require roughly double memory than that of what’s required to store the original weights. So the cost is really high.
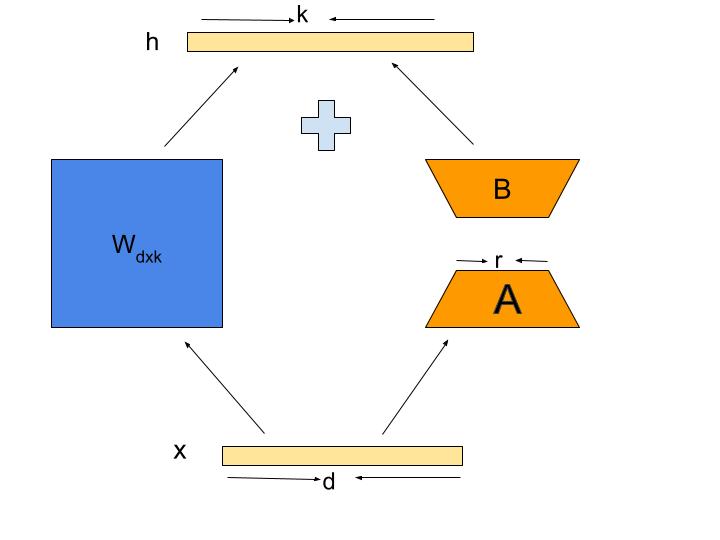
With LoRA this problem of cost has been tried to solve. It proposes a clever technique that uses matrix factorization operations which gradually reduce the amount of memory required to perform computation and to store the weights during model fine-tuning. It does this with the following steps:
Let’s consider original weight matrix as: \(W\)
With LoRA while fine-tuning the model instead of modifying all original weights we freeze them. We do not make any changes into them. Instead we “add” a separate set of weights(let’s call it \(\Delta W\)) to the original weights such as:-
\(W + \Delta W\)
One might wonder that this still will be equal to the original number of weights, just a bunch of different values.
So what is the LoRA trick here? How would it help reduce the amount of memory required to load the weights? Let’s move further to get the clarification:-
- The weights in any model are nothing but very big matrices of some size in the form: \(nRows X nColumns\). Thus in our case both the matrices \(W\) and \(\Delta W\) are of the size \(dXk\) (with \(d\) being the number of rows and \(k\) being the number of columns).
- Now every matrix has a rank. The maximum number of
linearly independentcolumns (or rows) of a matrix is called the rank of a matrix.linearly dependentmeans that we can get that column of the matrix by combining other columns of the matrix. For example below is a \(3X3\) matrix:
In here if we multiply the first column \(\begin{bmatrix} 1 \\ 2 \\ 2 \end{bmatrix}\) with \(2\) we can get the second column \(\begin{bmatrix} 2 \\ 4 \\ 4 \end{bmatrix}\). Thus these two columns become linearly dependent. And the third column remained as linearly independent.
- Now if we remove the linearly dependent column \(\begin{bmatrix} 2 \\ 4 \\ 4 \end{bmatrix}\), we can get this column by just multiplying the first column with \(2\). In this way we do not lose any information from our matrix and the matrix dimensions have been reduced.
- The trick what
LoRAdoes is that it removes the linearly dependent columns from the matrix to reduce its dimensions and thus the number of parameters.
In further technical terms LoRA’s idea is that we do not need to optimize the full rank matrices that have very high dimensions and a lot of parameters. Instead we do a low-rank decomposition in the following way:-
- Decompose the another weight matrix \(\Delta W\) of size \(dXk\) into 2 different matrices of lower dimensions: \(B * A\) where
- \(B\) is a matrix of size \(dXr\) and \(A\) is a matrix of size \(rXk\)
- \(r\) here represents the
intrinsic rankof the matrix - For example: Here assume \(W\) is a matrix of size \(100X100\) then total parameters of the matrix are: \(100*100 = 10000\). With this
LoRAtrick when we decompose the matrix into 2 matrices of size (assuming r being 3): \((100X3)\) and \((3X100)\). They collectively make \((100*3)+(3*100)=600\) parameters. - The effect of writing weight matrix \(\Delta W\) as the multiplication of 2 smaller matrices \(A\) and \(B\) is that we reduce the dimensionality of the weight matrix through \(A\) where we remove the
linearly dependentcolumns and We regain the original dimensionality through \(B\) - \(r\) is to be a hyperparameter which we need to choose because we don’t know what the rank of the original weight matrix \(W\) is. We hopefully remove the
linearly dependentcolumns through the \(B * A\) decomposition. If we choose \(r\) to be too small, we lose the dimensionality too much and so the information. If we choose \(r\) to be too big, we will be wasting computational resources as we will be keeping too many linearly dependent columns.
- We initialize the matrix \(A\) with a gaussian distribution and \(B\) with \(0\). Then as per our fine-tuning objective function we let the backprop figure out the right set of values for matrices \(A\) and \(B\).
- Thus instead of tuning the original large weight matrix \(W\), we tune the much smaller \(B\) and \(A\) matrices.
- After we have found the optimal weights for \(B\) and \(A\) we add this \(B * A\) matrix to the original weight matrix to make the inference.
A note about QLoRA: Quantized LoRA
QLoRA is an even more memory efficient version of LoRA where the pretrained model is loaded to GPU memory as quantized 4-bit weights (compared to 8-bits in the case of LoRA), while preserving similar effectiveness to LoRA. QLoRa works by first quantizing the LLM to 4-bit precision. This reduces the memory footprint of the LLM, making it possible to finetune it on smaller machines with less memory. QLoRa then adds a sparse set of learnable low-rank adapter weights to the quantized model. These adapters are updated during finetuning, allowing the model to retain its original performance.
Implementation: Fine-tuning Llama 2 with LoRA
Find the colab notebook for the same at: this link
!pip install -q accelerate==0.21.0 peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7
#import the required packages
import os, torch, logging
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline)
from peft import LoraConfig, PeftModel, PeftConfig, get_peft_model
from trl import SFTTrainer
# load dataset
dataset_name = "mlabonne/guanaco-llama2-1k"
dataset = load_dataset(dataset_name, split="train")
dataset
Output:-
Dataset({ features: [‘text’], num_rows: 1000 })
# Pre-trained Model name and finetuned model names
base_model_name = "NousResearch/Llama-2-7b-chat-hf"
fine_tuned_model = "llama-2-7b-finetuned"
# define the Tokenizer
llama_tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True)
llama_tokenizer.pad_token = llama_tokenizer.eos_token
llama_tokenizer.padding_side = "right"
print(llama_tokenizer.pad_token)
Output:-
\[</s>\]# Quantization Config
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False
)
# Load the pre-trained model
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name,
quantization_config=quant_config,
device_map={"": 0}
)
base_model.config.use_cache = False
base_model.config.pretraining_tp = 1
# LoRA Config
peft_parameters = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=8,
bias="none",
task_type="CAUSAL_LM"
)
# Training Params
train_params = TrainingArguments(
output_dir="./results_modified",
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant"
)
# Trainer to train the model
fine_tuning = SFTTrainer(
model=base_model,
train_dataset=dataset,
peft_config=peft_parameters,
dataset_text_field="text",
tokenizer=llama_tokenizer,
args=train_params
)
# Training starts here
fine_tuning.train()
"""
Output:-
[250/250 27:22, Epoch 1/1]
Step Training Loss
25 1.345300
50 1.617600
75 1.206000
100 1.438000
125 1.173000
150 1.360000
175 1.168900
200 1.458100
225 1.151400
250 1.528300
TrainOutput(global_step=250, training_loss=1.344664909362793, metrics={'train_runtime': 1660.126, 'train_samples_per_second': 0.602, 'train_steps_per_second': 0.151, 'total_flos': 8679674339426304.0, 'train_loss': 1.344664909362793, 'epoch': 1.0})
"""
# Save the fine-tuned Model
fine_tuning.model.save_pretrained(fine_tuned_model)
# let's generate some text
query = "why should someone be writing blogs about their field?"
text_gen = pipeline(task="text-generation", model=base_model, tokenizer=llama_tokenizer, max_length=200)
output = text_gen(f"[INST] {query} [/INST]")
print(output[0]['generated_text'])
"""
Output:-
<s>[INST] why should someone be writing blogs about their field? [/INST] There are several reasons why someone might want to write blogs about their field:
nobody knows everything, and sharing knowledge and insights can help establish oneself as an expert in their field.
1. Establish oneself as an expert: By consistently producing high-quality content, one can demonstrate their expertise and establish themselves as a thought leader in their industry.
2. Build credibility: Sharing valuable insights and information can help build credibility with potential clients, customers, or employers.
3. Networking opportunities: Writing a blog can provide opportunities to connect with other professionals in one's field, potentially leading to new business opportunities or collaborations.
4. Personal fulfillment: Writing about something one is passionate about can be a fulfilling hobby or creative outlet.
"""
# load the peft model
model = PeftModel.from_pretrained(base_model, fine_tuned_model)
# let's generate some text from the fine-tuned model
query = "why should someone be writing blogs about their field?"
text_gen = pipeline(task="text-generation", model=model, tokenizer=llama_tokenizer, max_length=200)
output = text_gen(f"[INST] {query} [/INST]")
print(output[0]['generated_text'])
"""
Output:-
<s>[INST] why should someone be writing blogs about their field? [/INST] There are several reasons why someone might want to write blogs about their field:
1. To share their expertise and knowledge with others. By writing blogs, they can help to educate and inform people about their field, and provide valuable insights and information.
2. To establish themselves as an authority in their field. By consistently producing high-quality blogs, they can demonstrate their expertise and build their reputation as a thought leader in their field.
3. To build their personal brand. By writing blogs, they can establish themselves as an expert in their field, and build their personal brand.
4. To generate leads and business opportunities. By writing blogs, they can attract potential customers and generate leads for their business.
5. To build a community around their field. By writing blogs, they can build a community of people who are
"""
Endnotes
Fine-tuning is a powerful technique that can be used to improve the performance of LLMs on specific tasks or domains. By fine-tuning LLMs, it is possible to create models that are tailored to the specific needs. However the fine-tuning process can be computationally expensive. Additionally, fine-tuning can lead to overfitting, which is a situation where the LLM learns the specific patterns in the training data too well and does not generalize well to unseen data.
Hope you enjoyed the post…
References
- LoRA paper: https://arxiv.org/abs/2106.09685
- https://arxiv.org/abs/2305.14314
- https://deci.ai/blog/fine-tune-llama-2-with-lora-for-question-answering/
- https://colab.research.google.com/drive/1PEQyJO1-f6j0S_XJ8DV50NkpzasXkrzd?usp=sharing#scrollTo=OJXpOgBFuSrc
- https://github.com/ShawhinT/YouTube-Blog/blob/main/LLMs/fine-tuning/ft-example.ipynb
- https://www.databricks.com/blog/efficient-fine-tuning-lora-guide-llms#:~:text=QLoRA%20is%20an%20even%20more,preserving%20similar%20effectiveness%20to%20LoRA.
- https://community.analyticsvidhya.com/c/generative-ai-tech-discussion/what-is-qlora