Multi-Modal Machine Learning - A beginner's guide
Content
- Overview: What is Multi-Modal Machine Learning?
- How does Multi-Modal Machine Learning work?
- Challenges
- Applications
- Code example - Image captioning
- Endnotes
- References
Overview: What is Multi-Modal Machine Learning?
In the past, machine learning models were typically trained on data from a single modality, such as text (BERT) or images(RESNET). However, as we collect more and more data from multiple sources, such as text, images, and audio, it is becoming increasingly important to develop machine learning models that can learn from data in multiple modalities. This is where multimodal machine learning comes in.
Multimodal machine learning is a type of machine learning that learns from data that comes in multiple modalities, such as text, images, and audio. These different types of data correspond to different modalities of the world, the ways in which it’s experienced by us, the humans. So for an ML model to be able to perceive the world in all of its complexity and understanding different modalities is a useful skill. For example look at the below image:

As humans we can immediately recognise that there is a cat(one modality) looking out of a window, probably of a plane’s window (second modality). Imagine how cool it would be for a machine learning model which instead of outputting just the classification of this image as a “cat”, gives a nice caption to this image as: “cat looking outside of a window” or “cat looking out in the ocean” etc.
Or the other way around where we give a description/caption as input to a model and it returns an image with that description.
While it’s true that analyzing multiple modalities at the same time is better than analyzing just one, it was too hard computationally to realize it before, it’s not anymore.
How does Multi-Modal Machine Learning work?
Although a Multi-Modal machine learning approach works the same way as for the single modality. There are common elements in both such as: Data, Feature extraction, Model training, Model evaluation, Model deployment etc. However "data representation and fusion" is something which makes multi modal machine learning different from the single modality. We discuss them in a little bit more detail below:-
Data representation and Fusion
Multimodal data can be represented in a variety of ways, and the choice of representation can have a significant impact on the performance of a multimodal machine learning model. For example, text data can be represented as a bag-of-words, a sequence of words, or a vector of word embeddings. Image data can be represented as a pixel matrix, a bag-of-visual words, or a convolutional neural network feature vector. Audio data can be represented as a time series, a spectrogram, or a mel-frequency cepstral coefficient (MFCC) feature vector. The choice of representation for multimodal data is often a trade-off between accuracy and computational complexity. More complex representations can often lead to more accurate models, but they can also be more computationally expensive to train and evaluate.
Fusion is the process of combining the features from different modalities into a single representation. This representation is used by the machine learning model to make predictions/decision making.
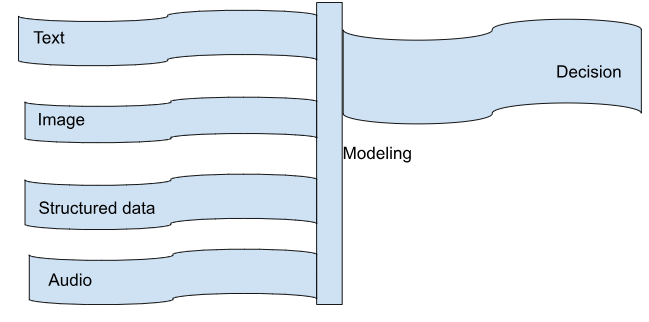
There are a variety of ways to fuse features, such as:
- Early fusion: Early fusion combines the features from different modalities at the beginning of the machine learning process. This is the simplest approach to fusion, but it can be less effective than other approaches.
- Late fusion: Late fusion combines the features from different modalities after the machine learning process has been completed. This is a more complex approach to fusion, but it can be more effective than early fusion.
- Hybrid fusion: Hybrid fusion is a combination of early fusion and late fusion. This approach can be more effective than early fusion or late fusion alone.
The choice of fusion approach will depend on the specific task at hand and the available data. However, in general, fusion can help to improve the performance, robustness, data efficiency, and interpretability of multimodal machine learning models.
Here are some examples of feature fusion in multimodal machine learning:
-
Image captioning: Image captioning is the task of generating a natural language description of an image. A multimodal machine learning model for image captioning might fuse the visual features of the image with the textual features of the caption to generate a more accurate and informative description.
-
Speech recognition: Speech recognition is the task of converting spoken language into text. A multimodal machine learning model for speech recognition might fuse the audio features of the speech with the textual features of the transcript to improve the accuracy of the recognition.
-
Natural language translation: Natural language translation is the task of translating text from one language to another. A multimodal machine learning model for natural language translation might fuse the textual features of the source text with the visual features of the target text to improve the accuracy of the translation.
Feature fusion is a powerful technique that can be used to improve the performance of multimodal machine learning models. By carefully choosing a fusion approach that is appropriate for the specific task at hand, we can develop more accurate and informative multimodal machine learning models.
Challenges
Let’s discuss some of the challenges which are posed by machine learning when done for multi modal purposes…
-
Representation: Multimodal machine learning models require data from multiple modalities to learn how to fuse the information from different sources. However, the data from different modalities may have different representations, which can make it difficult to combine the data into a single representation. For example, images may be represented as a sequence of pixels, while text may be represented as a sequence of words.
-
Limited data: Multimodal machine learning models require a lot of data to learn how to fuse the information from different sources. However, it can be difficult to obtain large datasets of multimodal data, especially for rare or niche tasks.
-
Missing modalities: In real-world applications, it is often the case that some of the modalities may be missing. For example, in a speech recognition task, the audio signal may be corrupted or the speaker may be wearing a mask, which can make it difficult to extract the audio features. In an image captioning task, the image may be blurry or the object of interest may be partially obscured, which can make it difficult to extract the visual features.
-
Scalability: Multimodal machine learning models can be computationally expensive and time-consuming to train, especially for large datasets and complex models. This is a particular challenge for tasks such as image classification and natural language processing, where the data may be very large and the models may be very complex.
-
Explainability: It can be difficult to explain the results of multimodal machine learning models. This is because the models are often complex and the features from different modalities may interact in non-obvious ways. To address this challenge, researchers are working on developing more explainable multimodal machine learning models. One promising approach is to use attention mechanisms, which can help to identify the features that the model is relying on to make its predictions. Another approach is to use visualization techniques, which can help to illustrate the decision-making process of the model.
Applications
Multimodal machine learning is a rapidly growing field with a wide range of applications. We can define some of the broad categories such as: Computer vision, Natural Language Processing, Robotics and many more. Below are some of the most common applications of multimodal machine learning:-
- Image captioning
- Speech recognition
- Natural language translation
- Object detection
- Activity recognition
- Sentiment analysis
- Virtual assistants
- Self-driving cars
Code example - Image captioning
——– Imports ——–
import time
from textwrap import wrap
import matplotlib.pylab as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
from tensorflow.keras import Input
from tensorflow.keras.layers import (
GRU,
Add,
AdditiveAttention,
Attention,
Concatenate,
Dense,
Embedding,
LayerNormalization,
Reshape,
StringLookup,
TextVectorization,
)
print(tf.version.VERSION)
Output: 2.12.0
——– Read and prepare dataset ——–
# Change these to control the accuracy/speed
VOCAB_SIZE = 20000 # use fewer words to speed up convergence
ATTENTION_DIM = 512 # size of dense layer in Attention
WORD_EMBEDDING_DIM = 128
# InceptionResNetV2 takes (299, 299, 3) image as inputs
# and return features in (8, 8, 1536) shape
FEATURE_EXTRACTOR = tf.keras.applications.inception_resnet_v2.InceptionResNetV2(
include_top=False, weights="imagenet"
)
IMG_HEIGHT = 299
IMG_WIDTH = 299
IMG_CHANNELS = 3
FEATURES_SHAPE = (8, 8, 1536)
Output:
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/inception_resnet_v2/inception_resnet_v2_weights_tf_dim_ordering_tf_kernels_notop.h5 219055592/219055592 [==============================] - 1s 0us/step
——– Filter and Preprocess ——–
GCS_DIR = "gs://asl-public/data/tensorflow_datasets/"
BUFFER_SIZE = 1000
def get_image_label(example):
caption = example["captions"]["text"][0] # only the first caption per image
img = example["image"]
img = tf.image.resize(img, (IMG_HEIGHT, IMG_WIDTH))
img = img / 255
return {"image_tensor": img, "caption": caption}
trainds = tfds.load("coco_captions", split="train", data_dir=GCS_DIR)
trainds = trainds.map(
get_image_label, num_parallel_calls=tf.data.AUTOTUNE
).shuffle(BUFFER_SIZE)
trainds = trainds.prefetch(buffer_size=tf.data.AUTOTUNE)
——– Text Preprocessing ——–
def add_start_end_token(data):
start = tf.convert_to_tensor("<start>")
end = tf.convert_to_tensor("<end>")
data["caption"] = tf.strings.join(
[start, data["caption"], end], separator=" "
)
return data
trainds = trainds.map(add_start_end_token)
——– Preprocess and tokenize the captions ——–
MAX_CAPTION_LEN = 64
# We will override the default standardization of TextVectorization to preserve
# "<>" characters, so we preserve the tokens for the <start> and <end>.
def standardize(inputs):
inputs = tf.strings.lower(inputs)
return tf.strings.regex_replace(
inputs, r"[!\"#$%&\(\)\*\+.,-/:;=?@\[\\\]^_`{|}~]?", ""
)
# Choose the most frequent words from the vocabulary & remove punctuation etc.
tokenizer = TextVectorization(
max_tokens=VOCAB_SIZE,
standardize=standardize,
output_sequence_length=MAX_CAPTION_LEN,
)
tokenizer.adapt(trainds.map(lambda x: x["caption"]))
# Lookup table: Word -> Index
word_to_index = StringLookup(
mask_token="", vocabulary=tokenizer.get_vocabulary()
)
# Lookup table: Index -> Word
index_to_word = StringLookup(
mask_token="", vocabulary=tokenizer.get_vocabulary(), invert=True
)
——– Create a tf.data dataset for training ——–
BATCH_SIZE = 32
def create_ds_fn(data):
img_tensor = data["image_tensor"]
caption = tokenizer(data["caption"])
target = tf.roll(caption, -1, 0)
zeros = tf.zeros([1], dtype=tf.int64)
target = tf.concat((target[:-1], zeros), axis=-1)
return (img_tensor, caption), target
batched_ds = (
trainds.map(create_ds_fn)
.batch(BATCH_SIZE, drop_remainder=True)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
——– Model ——–
——– Image Encoder ———
EATURE_EXTRACTOR.trainable = False
image_input = Input(shape=(IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS))
image_features = FEATURE_EXTRACTOR(image_input)
x = Reshape((FEATURES_SHAPE[0] * FEATURES_SHAPE[1], FEATURES_SHAPE[2]))(
image_features
)
encoder_output = Dense(ATTENTION_DIM, activation="relu")(x)
encoder = tf.keras.Model(inputs=image_input, outputs=encoder_output)
encoder.summary()
Output:
Model: “model”
Layer (type) Output Shape Param #
input_2 (InputLayer) [(None, 299, 299, 3)] 0
inception_resnet_v2 (Functi (None, None, None, 1536) 54336736
onal)
reshape (Reshape) (None, 64, 1536) 0
dense (Dense) (None, 64, 512) 786944
Total params: 55,123,680
Trainable params: 786,944
Non-trainable params: 54,336,736
——– Caption Decoder ——–
word_input = Input(shape=(MAX_CAPTION_LEN), name="words")
embed_x = Embedding(VOCAB_SIZE, ATTENTION_DIM)(word_input)
decoder_gru = GRU(
ATTENTION_DIM,
return_sequences=True,
return_state=True,
)
gru_output, gru_state = decoder_gru(embed_x)
decoder_atention = Attention()
context_vector = decoder_atention([gru_output, encoder_output])
addition = Add()([gru_output, context_vector])
layer_norm = LayerNormalization(axis=-1)
layer_norm_out = layer_norm(addition)
decoder_output_dense = Dense(VOCAB_SIZE)
decoder_output = decoder_output_dense(layer_norm_out)
decoder = tf.keras.Model(
inputs=[word_input, encoder_output], outputs=decoder_output
)
tf.keras.utils.plot_model(decoder)
decoder.summary()
——– Training Model ——–
image_caption_train_model = tf.keras.Model(
inputs=[image_input, word_input], outputs=decoder_output
)
——– Loss Function ——–
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction="none"
)
def loss_function(real, pred):
loss_ = loss_object(real, pred)
# returns 1 to word index and 0 to padding (e.g. [1,1,1,1,1,0,0,0,0,...,0])
mask = tf.math.logical_not(tf.math.equal(real, 0))
mask = tf.cast(mask, dtype=tf.int32)
sentence_len = tf.reduce_sum(mask)
loss_ = loss_[:sentence_len]
return tf.reduce_mean(loss_, 1)
image_caption_train_model.compile(
optimizer="adam",
loss=loss_function,
)
——– Training loop ——–
%%time
history = image_caption_train_model.fit(batched_ds, epochs=1)
Output: 2022-08-11 14:59:31.486203: W tensorflow/core/grappler/costs/op_level_cost_estimator.cc:690] Error in PredictCost() for the op: op: “Softmax” attr { key: “T” value { type: DT_FLOAT } } inputs { dtype: DT_FLOAT shape { unknown_rank: true } } device { type: “GPU” vendor: “NVIDIA” model: “Tesla T4” frequency: 1590 num_cores: 40 environment { key: “architecture” value: “7.5” } environment { key: “cuda” value: “11020” } environment { key: “cudnn” value: “8100” } num_registers: 65536 l1_cache_size: 24576 l2_cache_size: 4194304 shared_memory_size_per_multiprocessor: 65536 memory_size: 14467989504 bandwidth: 320064000 } outputs { dtype: DT_FLOAT shape { unknown_rank: true } } 2022-08-11 14:59:37.438484: I tensorflow/stream_executor/cuda/cuda_dnn.cc:368] Loaded cuDNN version 8200 2586/2586 [==============================] - 1006s 381ms/step - loss: 0.5751 CPU times: user 14min 59s, sys: 1min 45s, total: 16min 45s Wall time: 16min 46s
——– Caption! ——–
gru_state_input = Input(shape=(ATTENTION_DIM), name="gru_state_input")
# Reuse trained GRU, but update it so that it can receive states.
gru_output, gru_state = decoder_gru(embed_x, initial_state=gru_state_input)
# Reuse other layers as well
context_vector = decoder_atention([gru_output, encoder_output])
addition_output = Add()([gru_output, context_vector])
layer_norm_output = layer_norm(addition_output)
decoder_output = decoder_output_dense(layer_norm_output)
# Define prediction Model with state input and output
decoder_pred_model = tf.keras.Model(
inputs=[word_input, gru_state_input, encoder_output],
outputs=[decoder_output, gru_state],
)
MINIMUM_SENTENCE_LENGTH = 5
## Probabilistic prediction using the trained model
def predict_caption(filename):
gru_state = tf.zeros((1, ATTENTION_DIM))
img = tf.image.decode_jpeg(tf.io.read_file(filename), channels=IMG_CHANNELS)
img = tf.image.resize(img, (IMG_HEIGHT, IMG_WIDTH))
img = img / 255
features = encoder(tf.expand_dims(img, axis=0))
dec_input = tf.expand_dims([word_to_index("<start>")], 1)
result = []
for i in range(MAX_CAPTION_LEN):
predictions, gru_state = decoder_pred_model(
[dec_input, gru_state, features]
)
# draws from log distribution given by predictions
top_probs, top_idxs = tf.math.top_k(
input=predictions[0][0], k=10, sorted=False
)
chosen_id = tf.random.categorical([top_probs], 1)[0].numpy()
predicted_id = top_idxs.numpy()[chosen_id][0]
result.append(tokenizer.get_vocabulary()[predicted_id])
if predicted_id == word_to_index("<end>"):
return img, result
dec_input = tf.expand_dims([predicted_id], 1)
return img, result
filename = "../baseball.jpeg" # you can also try surf.jpeg
for i in range(5):
image, caption = predict_caption(filename)
print(" ".join(caption[:-1]) + ".")
img = tf.image.decode_jpeg(tf.io.read_file(filename), channels=IMG_CHANNELS)
plt.imshow(img)
plt.axis("off");
Output:
a baseball player with a catcher and umpire on top of a baseball field.
a baseball player is sliding into a base.
a baseball player swings at a pitch with the pitcher and umpire behind him.
baseball player with bat in the baseball game.
a batter in the process on the bat in a baseball game.

Endnotes
Multimodal machine learning is a rapidly growing field with the potential to impact many different industries. As the technology continues to develop, we can expect to see even more innovative and groundbreaking applications of multimodal machine learning in the months(not years) to come.
Hope you enjoyed the post…
References
- https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
- https://en.wikipedia.org/wiki/Residual_neural_network
- https://serokell.io/blog/multimodal-machine-learning
- https://github.com/GoogleCloudPlatform/asl-ml-immersion/blob/master/notebooks/multi_modal/solutions/image_captioning.ipynb